
某铁路信息中心运营监测项目
某铁路信息中心承担大量实时监测、例行巡检和排障维护等工作,为巩固信息化建设成果,提高整体运维效果,保障铁路信息系统稳定运行,需对现有网络监测系统进行升级改造。
设备类型:服务器、交换机、数据库、中间件、虚拟机、磁盘阵列、应用软件、操作系统、云平台等。
设备品牌:华为、H3C、深信服、MySQL、Oracle、Tomcat、JBoss、RabbitMQ、Nginx、中铁信安、联想、IBM、CentOS、Red Hat、Windows Server等。
功能需求:
- 实现数据中心与异地机房内不同品牌、型号的网络设备、服务器、存储设备等统一纳管;
- 提供详细的设备监控指标库,支持对不同设备的CPU、内存、磁盘、网口、温度等指标进行实时监控;
- 提供实时的设备掉线、链路断开告警;
- 自动定位故障位置和故障影响范围,提升排障效率;
- 具备告警分析管理能力,能够解决误报错报问题,提高告警准确度,可以通过多种途径触达告警信息;
- 提升例行巡检效率,自动化生成巡检月报、半年报、年报等报告;
- 解决现有工具下无法对业务系统、数据库、中间件的监控运维难题;
- 可以对日志数据进行梳理、解析,实现日志数据结构化存储展示并将异常转化为告警,解决日志信息复杂、难管理的问题;
- 解决人工进行设备配置管理工作量大且操作复杂的问题,能够快捷地对设备配置进行管理;
- 实现运维知识的积累,构建运维知识库。
智和信通方案
智和信通在深入理解某铁路信息中心的运维需求后,提出了一系列针对性的解决方案,旨在提升其监控运维平台的运行效率、稳定性和智能化水平,并通过此解决方案的实施助力信息中心运维工作更加高效、稳定地进行。
异地设备统一纳管
在网络可达范围内,仅需输入IP范围即可自动发现信息中心和异地机房中的各类设备,对设备进行统一纳管。
识别其厂商、型号,生成资源逻辑拓扑或真实面板图,匹配故障与性能监视器,并自动发现设备间连接关系,生成可视化链路,通过可视拓扑动态展示设备、链路的运行状态。
丰富且可扩展的监控指标库
针对某铁路信息中心的设备品牌和型号,在匹配我们标准模型库的基础上,通过SNMP、IPMI、SSH、Telnet等协议对设备及监控指标进行扩展。
- 对服务器的监控指标:服务器品牌、型号、序列号、开机时长、CPU使用率、内存使用率、硬盘容量、磁盘使用率、磁盘容量预测、磁盘I/O、电源状态、温度信息、风扇状态、网络接口流量带宽等;
- 对交换机的监控指标:交换机品牌、型号、CPU使用率、内存使用率、电源状态、风扇状态、端口流量、网口状态、网口输入输出流量、网口输入输出带宽等;
- 对数据库的监控:表空间、锁数量、死锁、并发数、连接数、缓存命中率、读写次数、读写速度、读命中率、已用空间、最大空间等。
- 对中间件的监控:线程数、内存占用量、会话数、繁忙线程数量、请求服务数、请求服务错误数、连接数等。
- 对虚拟机的监控:虚拟机类型、CPU使用率、内存使用率、磁盘使用率、磁盘容量、网口状态、网口输入输出流量、网口输入输出带宽等。
- 对磁盘阵列的监控:CPU使用率、内存使用率、磁盘空间使用率、磁盘I/O、网口状态、接口流量等。
- 对操作系统的监控:Ping、CPU使用率、内存大小、内存使用率磁盘空间、磁盘使用率、网口状态、发送/接收流量、发送/接收带宽、发送/接收丢包率、发送/接收错误包率、广播包故障率、进程状态、端口状态等。
- 对云平台的监控:磁盘可用资源、内存使用率、CPU使用率、吞吐量等。
全面的告警管理,支持多种通知方式
支持多种告警机制,自定义配置告警阈值,具备主动的故障监控告警功能,第一时间获取准确的告警信息,快速标示已执行操作的告警,迅速定位告警设备,提升告警处理效率,极大降低因网络故障带来的损失。
采用自动去重、风暴抑制、关联聚合、维护期时间屏蔽、依赖屏蔽等多种智能告警降噪机制,对各类告警进行自动压缩收敛,有效避免误报和漏报。告警发生后,检索异常问题关联涉及的各项维度与影响范围,一步定位到发生故障的源头设备,快速定位故障根因。提供界面颜色、提示声、光效闪烁、信息列表、Email、短信、钉钉、企业微信、个人微信等多种通知渠道,告警通知无延迟。
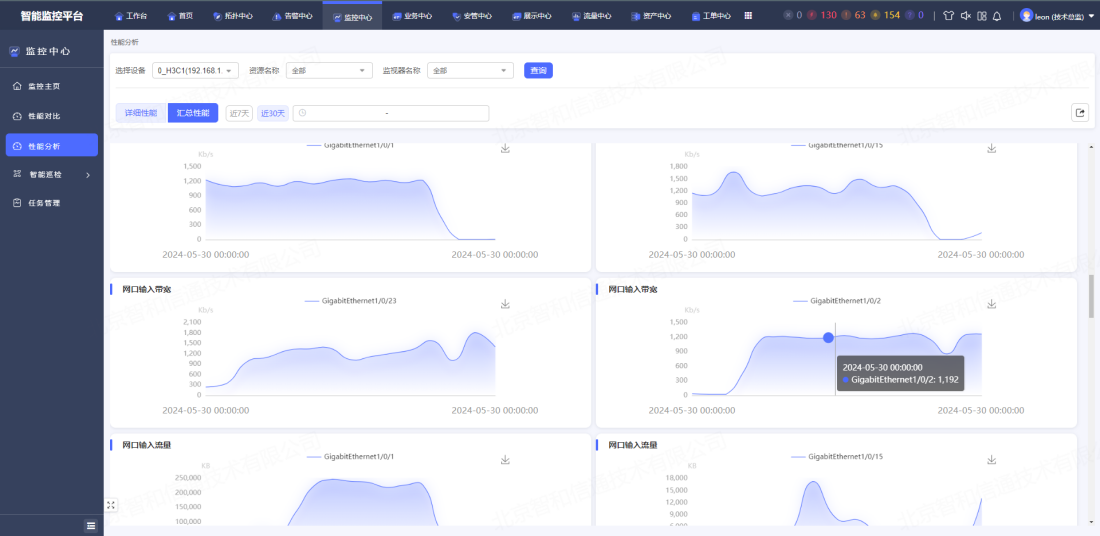
多维度性能管理,感知网络状态
实时监测并感知网络性能状态,全面覆盖用户IT环境。采集纳入监控的服务器、交换机、数据库、中间件、虚拟机、磁盘阵列、应用软件、操作系统、云平台等设备的性能指标。支持对实时、历史性能数据进行统计分析,通过曲线图、柱状图或表格等形象化地展示,按天、星期、月查看性能指标变化。
设备事件、日志集中管理
全面设备主动发送的Trap、Syslog、Filter Alarm等事件与日志消息,进行集中存储和解析并提取有效信息,将日志存储为可统计分析的结构化数据。根据对日志数据的挖掘与分析,通过配置告警规则和场景,将异常日志自动转化为告警,定位其影响范围。
端到端业务拨测,构建业务依赖关系图片
针对用户货运系统、调度系统、车流服务等业务应用性能与用户体验进行检测分析,以拓扑形式展示每个业务流程中的每台相关设备。按照硬件层-虚拟化层-应用服务层-接口层-数据层-界面层-用户层等建立业务依赖关系图谱,并以可视化的方式直观表达各层级对下层的依赖关系,以及同级之间的依赖关系。
对从业务的前台受理到真正完成的整个业务流程所依赖的业务应用、服务器、中间件、数据库、操作系统等进行实时监控分析,呈现业务各节点的实时运行状态,包括用户体验、节点可用性、节点负载等状态信息,快速定位业务瓶颈根因,并可根据用户自愈策略,触发自动运维实现故障自愈。
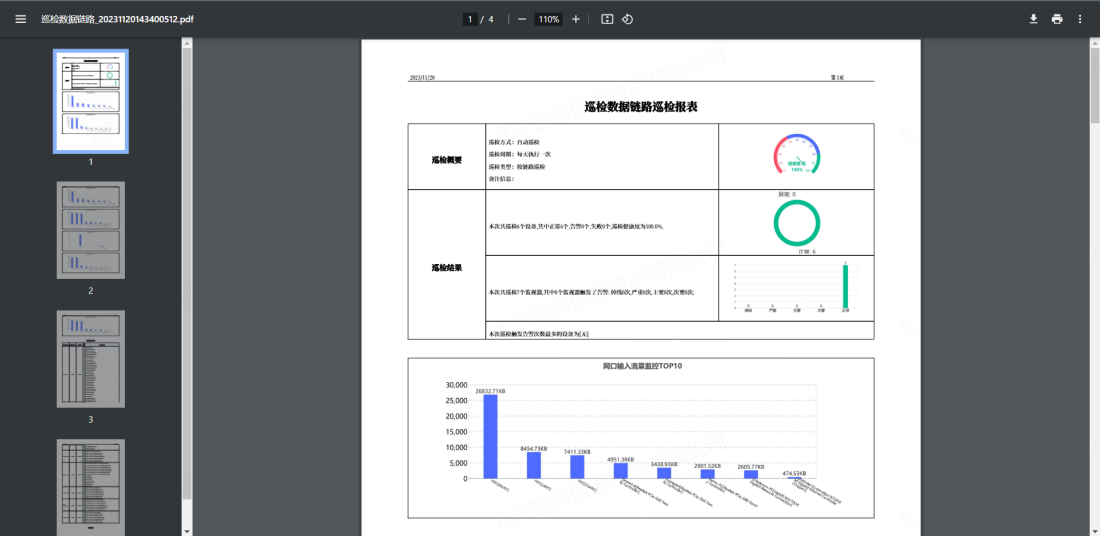
全量自动巡检,解放人力
支持自定义巡检策略,对设备的运行情况进行统计和报表生成,并可预设时间巡检策略执行时间,进行自动化巡检,如自动每周、每月、每年的固定时间对设备当前状态进行巡检,可向指定邮箱发送巡检结果报告,实现对网络设备的定期检查,把握网络运行中的易出现问题的环节,做到预防为先。
设备远程控制,配置文件备份对比
将周期性、重复性、规律性的大量日常服务器配置工作,如批量分发配置文件、一键开关机、进程管理、应用管理、端口限速、ACL配置等,转化为依托于平台的自动执行工作流,实现对服务器的批量、定时等自动化控制。
也支持配置文件批量备份、下载、周期性备份、查看等,对设备的多个备份文件进行对比。定期自动对设备策略进行巡检备份,并可进行对比分析。
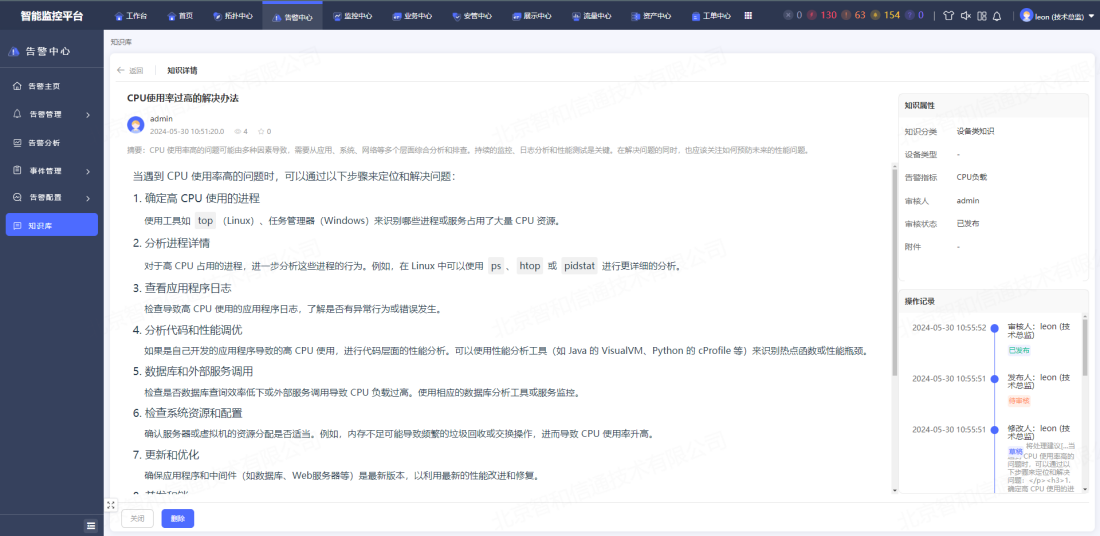
构建运维知识库,促进知识共享协作
将各类运维操作、故障判断等经验,转化为存在于平台内的知识,形成团队知识库。涵盖知识的存储、检索、更新、维护、审核,将运维工作中所需的运维文档、操作指南、排障实践、处置流程和配置信息等进行分类管理,所有成员均可进行知识分享,从而加速问题解决过程,促进团队间的知识共享和协作,提升整体运维效率。
应用价值
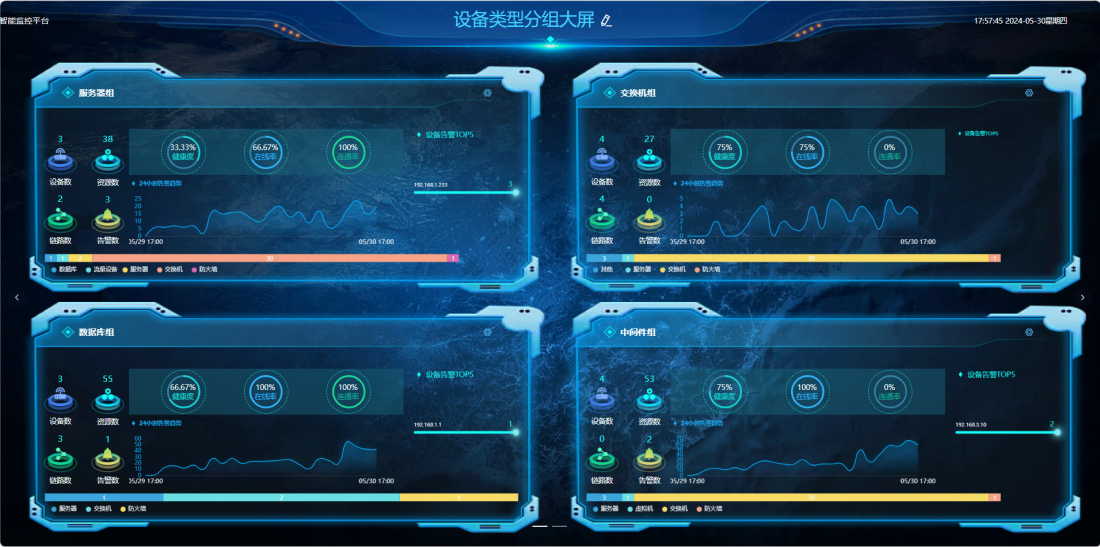
过去某铁路信息中心网络监测工作主要依赖于传统的巡检和人工排查方式,在引入智和信通运维监测平台对网络监测系统升级改造后,不仅实现了对某铁路信息中心网络的运行状态进行实时监控,更实现了全自动巡检和设备远程配置管理,不但有效预测并防止潜在故障的发生,也标志着其运维方式从传统的巡检和人工排查方式向智能化、自动化运维管理的转变。
通过智和信通运维监测平台实时了解网络设备的运行状况、网络流量的变化情况及网络拓扑结构的变化等信息,无需再到现场进行巡检,不仅提高了工作效率,也降低了工作成本。同时,对信息中心网络的运行数据进行深入挖掘和分析,提供更加准确、全面的故障预测和预警,及时发现网络中的潜在故障点,通过多种报警方式,如短信、邮件钉钉、微信等,确保用户能够及时接收到故障信息并采取相应的处理措施。避免故障扩大化,减少由于设备故障或网络问题导致的铁路事故。除了实时监控和故障预警外,智和信通运维监测平台还提供了丰富的管理功能。通过平台对网络设备进行远程管理和配置,实现设备的自动化管理和维护。
在智和信通运维监测平台的部署和应用后,不仅依托于强大的数据分析和处理能力,使得用户可以更加精准地定位故障源头,并采取有效的措施进行修复,大大提高了运维工作效率,也减少因故障带来的损失。同时,通过自动化和智能化的运维管理,降低了对人力资源的依赖。运维人员无需再频繁地进行手动巡检和排查,而是可以通过平台自动生成的报告和数据分析结果,快速了解网络的运行状况,极大地提高了运维工作的质量和稳定性。

